
[译]让 AI 在复杂代码库中发挥作用

业界普遍认为,AI 编程工具在处理真实生产环境代码库时表现欠佳。 斯坦福大学关于 AI 对开发者生产力影响的研究指出:
许多由 AI 工具生成的“额外代码”最终只是在重做上周产出的粗糙内容。
编程助手虽适用于新项目或小规模改动,但在大型成熟代码库中,反而可能降低开发者的效率。
常见的反应介于悲观派的“这永远行不通”与审慎派的“或许未来出现更智能模型时可行”之间。
经过数月实践,我发现只要掌握核心的上下文工程原则,现有模型就能发挥巨大潜力 。
这并非又一篇“十倍提升生产力”的宣传稿。 面对人工智能的热潮,我一向持审慎态度 。但我们偶然发现的工作流程,让我对未来的可能性充满信心。我们已实现让 Claude 代码处理 30 万行规模的 Rust 代码库,单日完成相当于一周的工作量,并且代码质量经得起专家审核。这得益于一套名为“高频定向压缩”的技术体系——即在开发过程中刻意构建向 AI 输送上下文的方式。
我现在完全确信,编程 AI 不仅适用于玩具和原型开发,更是一门精深的技术工程技艺。
来自 AI 工程师的实践基础
2025 年 AI 工程师大会的两场演讲从根本上重塑了我对这个问题的认知。
其一是肖恩·格罗夫关于“规范即新代码”的演讲 ,其二是斯坦福大学关于 AI 对开发者生产力影响的研究 。
肖恩指出我们都在错误地进行氛围编程 。那种花两小时与 AI 代理聊天、详细说明需求,最后仅提交最终代码而丢弃所有提示词的做法……就像 Java 开发者编译 JAR 包后,仅提交编译好的二进制文件却丢弃源代码一样荒谬。
肖恩提出,在人工智能主导的未来,技术规格将成为真正的代码。两年后,你在 IDE 中打开 Python 文件的频率,大概会像如今打开十六进制编辑器阅读汇编代码一样罕见(对大多数人来说,这种情况根本不会发生)。
叶戈尔关于开发者生产力的演讲探讨了一个正交性问题。他们分析了 10 万名开发者的提交记录,发现其中存在诸多现象,
人工智能工具常常导致大量返工,削弱了人们感知到的生产力提升


人工智能工具对于新项目效果显著,但在处理遗留代码库和复杂任务时往往适得其反


这与我和创始人交流时听到的情况相符:
“过于松散。”
“技术债务工厂。”
“不适用于大型代码库。”
“不适用于复杂系统。”
当前业界对 AI 编程处理复杂任务的普遍态度往往是
也许有一天,当模型更智能时……
就连阿姆贾德九个月前也在莱尼的播客节目上谈到,产品经理如何运用 Replit 智能体快速原型开发,随后交由工程师进行生产环境部署。(声明:我最近(好吧,从未)没和他联系过,这一立场可能已有变化)
每当我听到“也许有一天模型变得更聪明时”,我总会忍不住大声强调这正是情境工程的核心所在 :充分挖掘当下模型的潜力。
当前实际可实现的技术边界
后续我会深入探讨,但为证明这不只是理论,容我简述一个具体案例。几周前,我决定在 BAML 上测试我们的技术——这是一个 30 万行 Rust 代码库的编程语言项目,专门用于 LLMs 开发。作为 Rust 初学者,我此前从未接触过 BAML 代码库。
大约一小时内,我就完成了代码提交,并在次日早晨获得了维护者的批准。几周后,@hellovai 与我协作向 BAML 提交了 3.5 万行代码,新增了功能模块——团队预估每个功能都需要资深工程师花费 3-5 天完成。我们仅用约 7 小时就完成了两个 PR 草案。
这一切都围绕我们称之为频繁定向压缩的工作流程构建——本质上是将整个开发流程设计为围绕上下文管理展开,将利用率保持在 40%-60% 区间,并在关键节点设置高效的人工审核机制。我们采用”研究、规划、实现”的工作流,但这里的核心能力/经验远比任何具体工作流或提示集更具普适性。
我们抵达此处的奇妙历程
我曾与一位我见过最高效的 AI 程序员共事。每隔几天,他们就会提交长达 2000 行的 Go 语言 PR。这可不是什么 nextjs 应用或 CRUD 接口,而是通过 Unix 套接字进行 JSON RPC 通信、管理分叉 Unix 进程(主要是 Claude 代码 SDK 进程,后续详述🙂)流式标准输入输出的复杂且易出现竞态条件的系统级代码 。
每隔几天仔细阅读 2000 行复杂的 Go 代码的想法显然不可持续。我开始有点体会到米切尔·哈希莫蒂为 ghostty 添加规则时的心情了。
我们的方法是采用类似肖恩的规范驱动开发 。
起初这让人不太适应。我必须学会不再逐行审阅 PR 代码。虽然我仍然会仔细阅读测试部分,但技术规范已成为我们判断功能构建内容及原因的主要依据。
转型过程持续了约八周。对所有参与者来说都极为煎熬,尤其对我而言。但现在我们已驾轻就熟。几周前,我曾在一天内提交了 6 个 PR。过去三个月里,我手动编辑非 Markdown 文件的次数屈指可数。
面向编程智能体的高级上下文工程
我们所需的是:
能在遗留代码库中表现出色的 AI
能解决复杂问题的 AI
杜绝粗制滥造
保持团队间的心智对齐
(当然,我们也尽量充分利用令牌资源。)
我将深入探讨:
我们在将上下文工程应用于编程智能体过程中的收获
在这些维度上运用这些智能体是一项高度专业的技术工艺
为何我认为这些方法不具备普适性
我关于第三点被反复证错的次数
但首先:管理智能体上下文的初级方法
我们大多数人最初会使用像聊天机器人这样的编程助手。你与它来回对话(或者醉醺醺地嚷嚷 ),在解决问题的过程中逐渐磨合,直到上下文耗尽、选择放弃,或是助手开始道歉为止。

稍微聪明些的做法是在偏离轨道时直接重启,丢弃当前会话并开启新对话,或许在提示词中多加些引导。
[原始提示词],但务必采用 XYZ 方法,因为 ABC 方法行不通

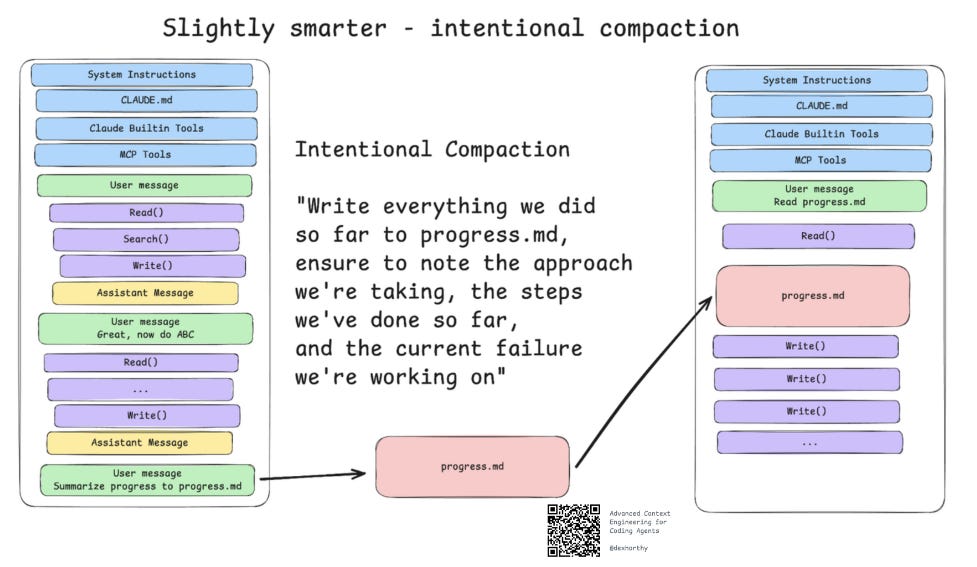
略胜一筹:有意识压缩法
你可能已经做过我称之为“有意压缩”的事情。无论进展是否顺利,当上下文开始占满时,你或许会想暂停工作,重新开启一个干净的上下文窗口。为此,你可能会使用这样的提示:
“将我们目前完成的所有内容写入 progress.md,务必注明最终目标、我们采取的方法、已完成的步骤以及当前正在解决的故障”
你也可以利用提交信息进行有意压缩 。
我们究竟在压缩什么?
什么会消耗上下文?
正在搜索文件
理解代码流程
应用编辑
测试/构建日志
来自工具的庞大 JSON 数据块
所有这些都可能淹没上下文窗口。 压缩就是将它们提炼成结构化工件的过程。
一个良好的有意压缩输出可能包含类似这样的内容

为何要执着于上下文?
正如我们在十二要素智能体中深入探讨的那样,LLMs 本质上是无状态函数。在不涉及模型训练/调优的情况下,唯一影响输出质量的就是输入质量。
这一原则对于驾驭编程智能体同样适用,只是问题空间更小。我们讨论的重点并非构建智能体,而是如何有效使用智能体。
在任何时刻,像 Claude Code 这样的智能体的每次交互都是一次无状态函数调用。上下文窗口输入,下一步输出。
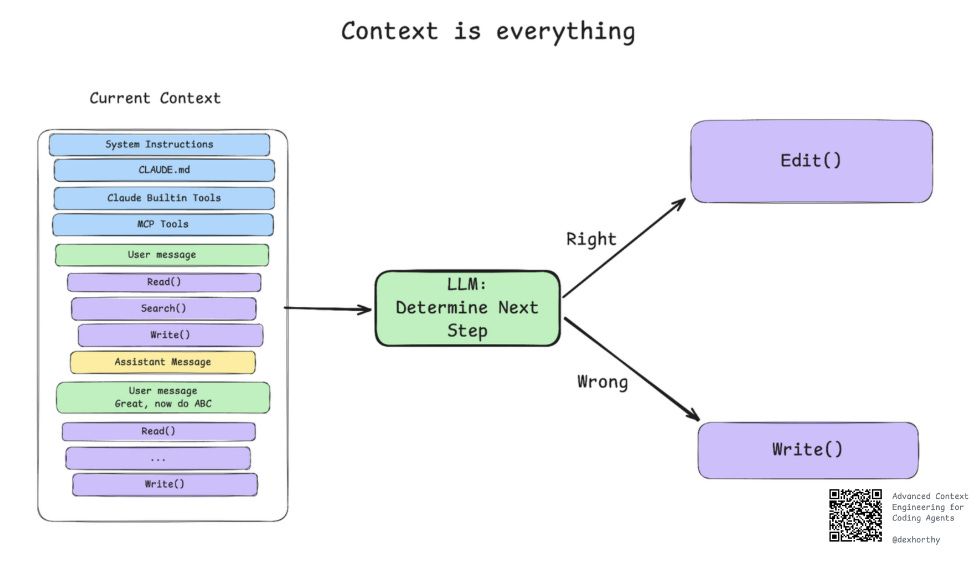
也就是说,上下文窗口的内容是影响输出质量的唯一可控因素。因此,确实值得投入精力去精心设计。
你应当从以下维度优化上下文窗口:
准确性
完整性
规模
轨迹
换言之,上下文窗口可能遭遇的最糟糕情况,按严重程度依次为:
信息不准确
信息缺失
信息干扰过多
若您偏好公式表述,这里有个可供参考的简易示例:

正如 Geoff Huntley 所言,
核心要点在于,你仅有约 17 万字符的上下文窗口可供使用。因此必须尽可能精简使用。上下文窗口占用越多,最终效果就越差。
针对这一工程限制,Geoff 提出的解决方案被他称为 “软件工程师拉尔夫·威格姆”,其本质是通过简单提示词让智能体在无限循环中持续运行。
while :; do
cat PROMPT.md | npx --yes @sourcegraph/amp
done
若想深入了解拉尔夫机制或 PROMPT.md 的细节,可查阅 Geoff 的博文,或探究上周 YC 智能体黑客松上由 @simonfarshid、@lantos1618、@AVGVSTVS96 与我共同构建的项目——该项目基本实现了 “一夜之间将 BrowserUse 移植到 TypeScript”。
Geoff 将 ralph 描述为解决上下文窗口问题的一个“滑稽又愚蠢”的方案。 我并不完全认同这个方案很愚蠢 。
{kind=link}
回到压缩策略:使用子代理(Sub-Agents)
子代理是管理上下文的另一种方式,通用子代理(即非定制型)自早期以来一直是 Claude 代码及众多编程 CLI 的功能特性。
子代理的核心并非角色扮演或拟人化分工 ,而在于上下文控制。
子代理最常见且直接的用途是让你利用全新的上下文窗口进行查找、搜索和汇总操作,使主代理能够直接投入工作,而无需因 Glob、Grep、Read 等调用污染其上下文窗口。
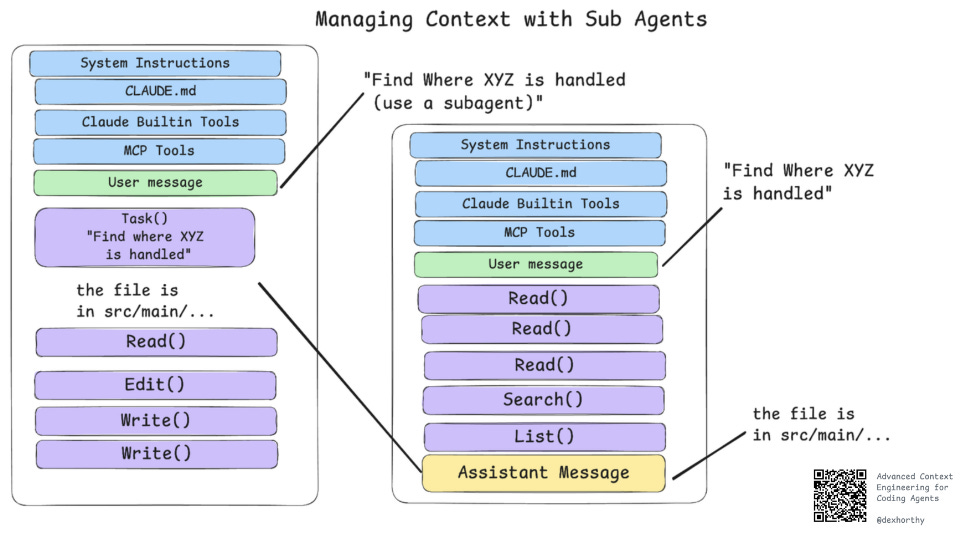
理想的子代理响应可能与上述理想的临时压缩类似。

让子代理返回这样的响应并非易事:

更有效的方法是:频繁有意的压缩
我想讨论的这些技术,以及我们在过去几个月里采用的方法,都属于我称之为“频繁有意压缩”的范畴。
本质上,这意味着围绕上下文管理来设计你的整个工作流程,并将利用率保持 在 40%-60% 的范围内(具体取决于问题的复杂度)。
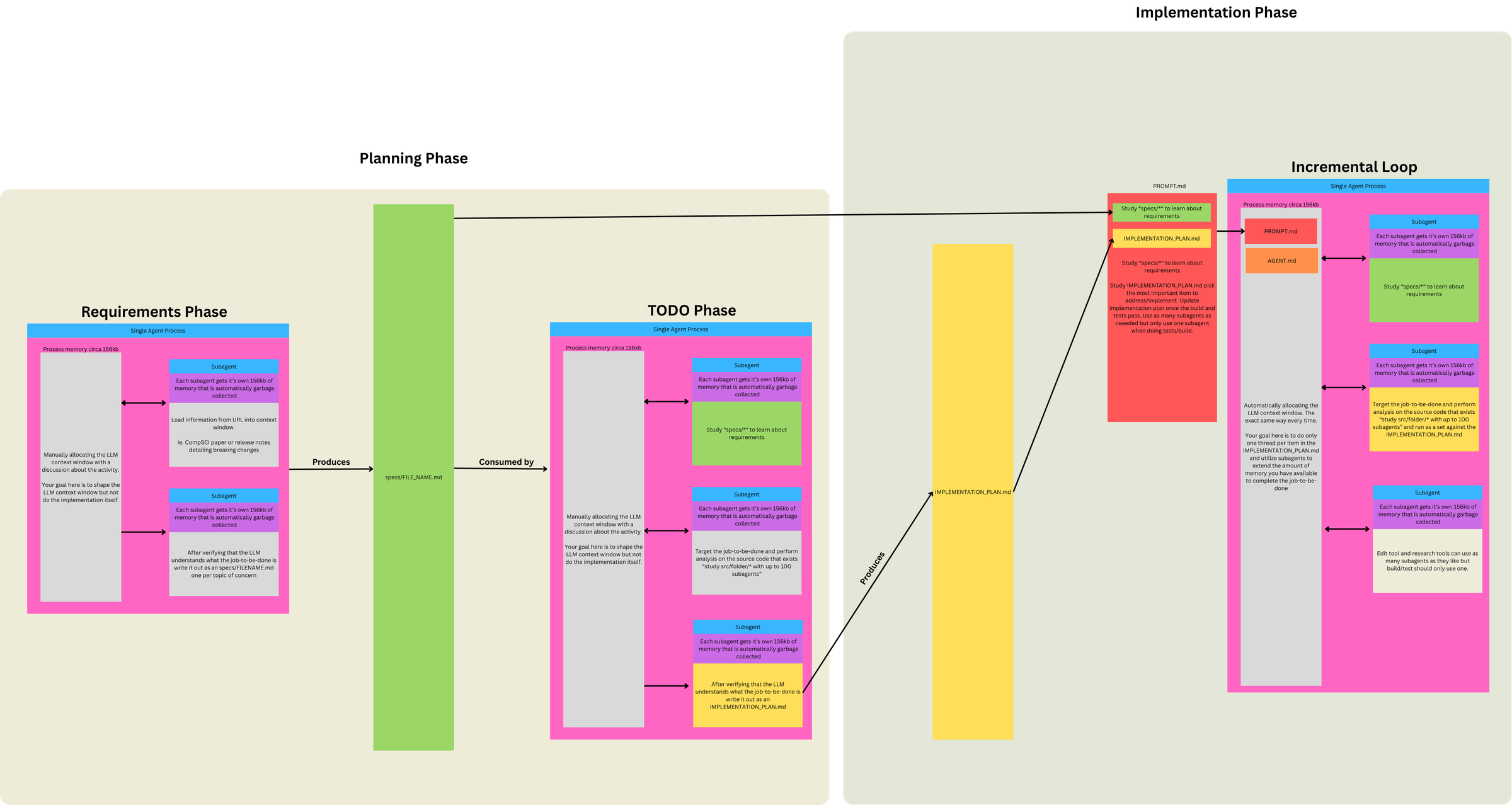
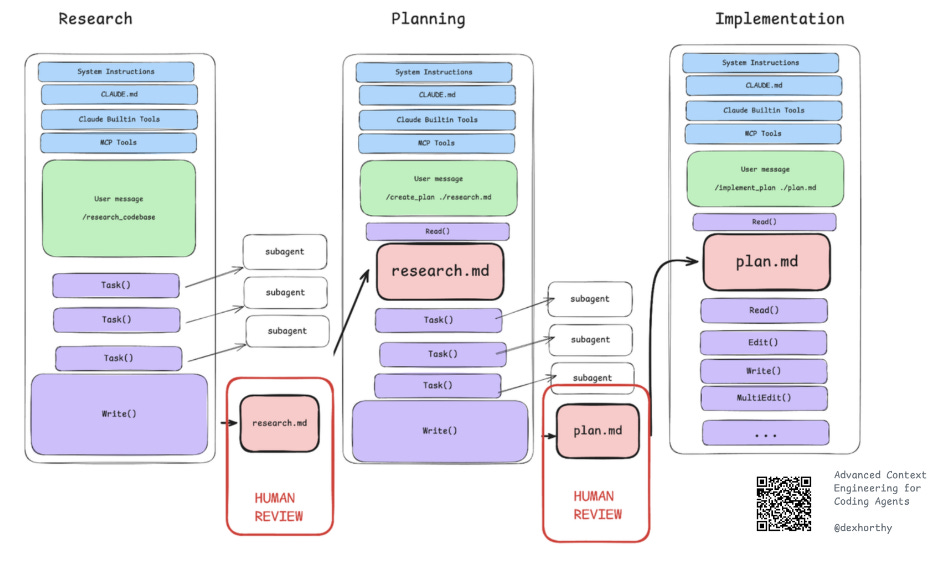
我们的做法是将流程分为三个(大致)步骤。
之所以说“大致”,是因为有时我们会跳过调研直接进入规划阶段,而有时在准备实施前会进行多轮浓缩式调研。
下面我将通过具体案例展示每个步骤的示例输出。针对某个功能或缺陷,我们通常会进行以下操作:
研究
理解代码库、与问题相关的文件以及信息流动方式,或许还包括问题的潜在原因。
这是我们研究提示 。目前它使用自定义子代理,但在其他代码库中,我使用更通用的版本,该版本通过 general-agent 调用 claude 代码 Task()工具。通用版本的效果几乎同样出色。
规划
概述我们将采取的精确步骤来解决问题,以及需要编辑的文件和具体操作方法,对每个阶段的测试/验证步骤进行极其详细的说明。
这是我们用于规划的提示词 。
实施
按阶段逐步执行计划。对于复杂的工作,我通常会在每个实施阶段验证完成后,将当前状态压缩回原始计划文件中。
这是我们使用的实现提示 。
补充说明——如果您最近常听说 git 工作树,这是唯一需要在工作树中完成的步骤。我们倾向于在主分支上进行其他所有操作。
我们如何管理/共享 markdown 文件
为简洁起见,这部分我将略过,但您可以在 humanlayer/humanlayer 中启动 claude 会话,询问“思考工具”的运作原理。
将此付诸实践
我与 @vaibhav 每周都会进行一次实时编程直播 ,期间我们会通过白板讨论并编写代码来解决高级 AI 工程问题。这是我每周最期待的时刻之一。
几周前,我决定进一步分享这个过程 ,想验证我们的内部技术能否一次性修复 BAML(一种用于处理 LLMs 的编程语言)这个拥有 30 万行代码的 Rust 项目。我从@BoundaryML 代码库中挑选了一个( admittedly 规模较小的)bug 开始着手。
您可以观看这期节目了解详细过程,简要概括如下:
值得注意 :我顶多算个 Rust 编程的业余爱好者,且从未接触过 BAML 的代码库。
这项研究
我撰写了一份研究报告并进行了审阅。Claude 判定该缺陷无效,认为代码库是正确的。
我摒弃了那份报告,重新启动了一项更具指导性的研究。
这里是我最终采用的研究报告文档
计划
这两份方案篇幅都不长,但差异显著。它们以不同方式修复问题,并采用不同的测试方法。简而言之,两者都“本可奏效”,但基于研究的方案在最恰当的位置解决了问题,且制定的测试方案符合代码库规范。
实施过程
这一切都发生在播客录制前夜。我并行执行了两个方案,并在当晚提交了两个拉取请求后才休息。
等到第二天太平洋时间上午 10 点我们上节目时,对方甚至不知道我这是为播客准备的小插曲🙂。我们关闭了另一个方案 。
最初设定的四个目标中,我们实现了:
✅ 适用于遗留代码库(30 万行 Rust 项目)
解决复杂问题
✅ 无冗余代码(PR 已合并)
保持思维一致性
解决复杂问题
瓦伊巴夫仍然持怀疑态度,我想看看我们能否解决更复杂的问题。
于是几周后,我们两人花了 7 小时(3 小时研究规划,4 小时实施),提交了 3.5 万行代码,为 BAML 增加了取消操作和 WebAssembly 支持。虽然取消功能的 PR 还需要进一步完善,但我们已经实现了在浏览器中通过 JS 应用调用 wasm 编译的 Rust 运行时的可运行演示。
尽管取消功能的 PR 还需要稍加完善才能最终完成,但我们在短短一天内取得了惊人进展。瓦伊巴夫估计,BAML 团队的高级工程师完成每个这样的 PR 通常需要 3-5 个工作日。
✅ 所以我们也能解决复杂问题。
这并非魔法
还记得例子中我读完研究后直接弃用的部分吗?因为那份研究有误。或者我和 Vaibhav 全神贯注投入 7 小时的场景?进行这类工作时必须全身心投入,否则注定失败。
总有这样一类人,他们始终在寻找能解决所有问题的“万能提示词”。这种东西根本不存在。
通过研究/规划/实施流程进行频繁的有意压缩会让你的表现更好 ,但真正使其足以应对难题的关键在于,你在流程中构建了高效的人工审核环节。
颜面尽失
几周前,@blakesmith 和我花了 7 个小时尝试从 parquet java 中移除 hadoop 依赖项 ——关于所有出错细节的深度剖析以及我的原因分析,我会留到后续文章再详述,简而言之结果并不理想。核心问题在于研究阶段未能深入依赖树底层,误以为可以将类文件向上游迁移而不会引入深层嵌套的 hadoop 依赖。
有些艰巨难题无法仅靠七小时的即时提示解决,我们仍在与伙伴们满怀好奇与激情地探索技术边界。我认为另一个启示是:团队中至少需要一位代码库专家,而这次我们双方都非此类专才。
关于人力杠杆
若要从这一切中汲取一点心得,那便是:
一行糟糕的代码终究只是一行糟糕的代码。但若规划中出现疏漏,便可能衍生出数百行问题代码。而调研阶段的失误——比如误解代码库运作机制或功能模块位置——更可能引发数千行代码的连锁问题。
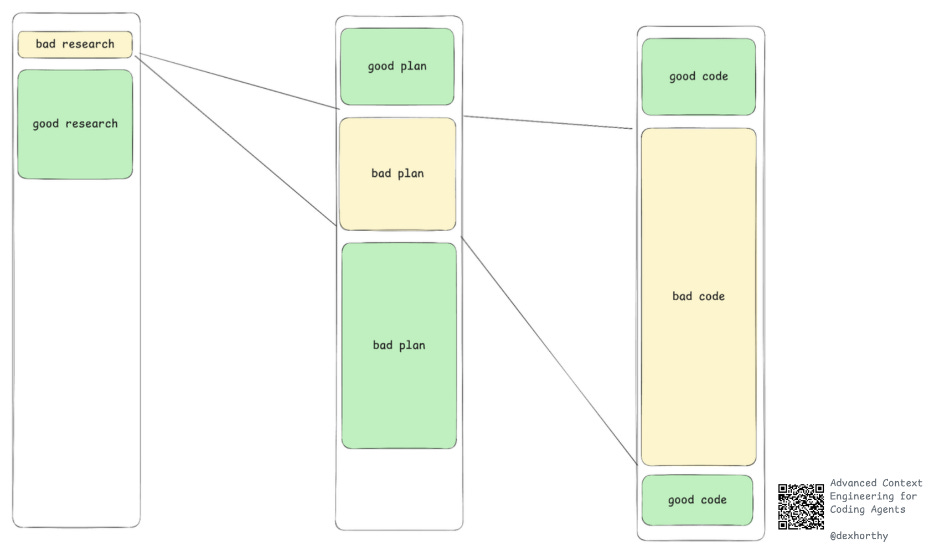
所以你想将人力投入和注意力集中在流程中最高效能的环节上。
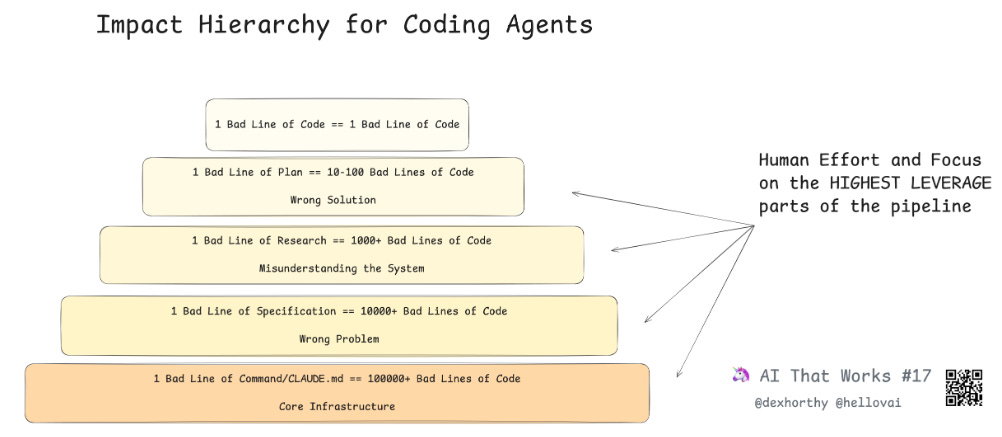
当你审阅研究结果和计划时,获得的效能提升远高于代码审查阶段。(顺带一提,我们 humanlayer 的核心目标之一就是帮助团队构建并运用高质量的工作流提示,为 AI 生成的代码和规范打造卓越的协作流程。)
代码审查的目的是什么?
关于代码审查的目的,人们众说纷纭。
我更喜欢 Blake Smith 在《软件团队代码审查精要》中的表述 ,他认为代码审查最重要的部分是思维对齐——让团队成员对代码的变更方式和原因保持同步。
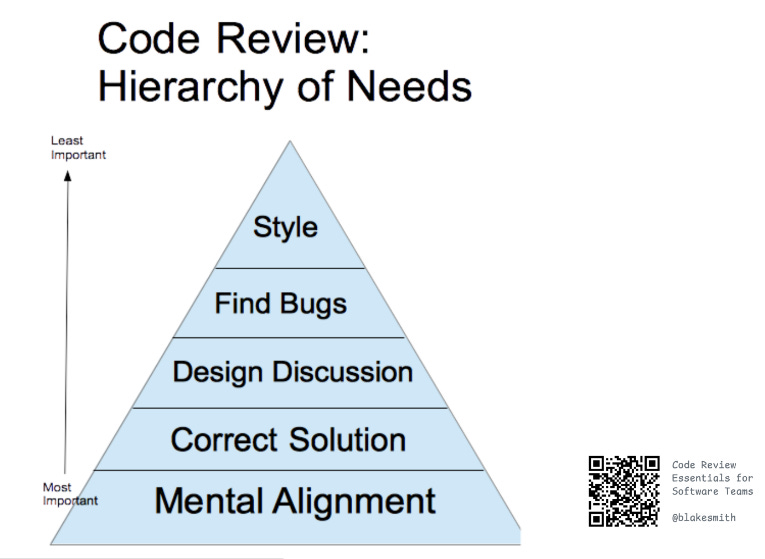
还记得那些两千行的 Go 语言 PR 吗?我关心它们的正确性和设计优良性,但团队内部最大的不安和挫败感来源正是思维对齐的缺失。 我开始逐渐不了解我们的产品及其运作方式了。
我相信任何与高效 AI 编码工具合作过的人都有过这种体验。
这实际上是我们研究/规划/实施过程中最重要的环节。当每个人交付的代码量激增时,必然会产生一个副作用:在任何时间点,代码库中更大比例的内容对任何工程师来说都会变得陌生。
我甚至不会试图说服你“研究/规划/实施”是适合大多数团队的正确方法——很可能并非如此。但你们绝对需要一个工程流程,它能够
确保团队成员保持同步
帮助团队成员快速熟悉代码库中陌生的部分
对大多数团队而言,这体现在代码审查和内部文档上。对我们来说,现在则体现在规范说明、实施计划和前期研究中。
我无法每天阅读 2000 行 Go 语言代码。但我能够阅读 200 行精心编写的实施方案。
当系统出现故障时,我无法花一个多小时在 40 多个守护进程代码文件中艰难排查(好吧,我能做到,但我不愿意)。我能够通过研究提示快速定位问题根源及其原因。
回顾
基本上我们已经获得了所有需要的内容。
✅ 适用于遗留代码库
✅ 解决复杂问题
✅ 杜绝冗余代码
✅ 保持思维一致性
(哦,对了,我们三人团队每月在 Opus 上的平均花费大约是 1.2 万美元。)
为了证明我并非那种夸夸其谈的推销员 ,我要说明这种方法并非万能(后续我们还会讨论 parquet-java 相关的案例)。
八月份整个团队花了整整两周时间在一个棘手的竞态条件问题上原地打转,这个问题最终演变成涉及 golang 中 MCP sHTTP 长连接的难题,还引发了一系列其他无解的状况。
但这只是特例。总体而言,这套方案对我们非常有效。实习生上岗首日就提交了 2 个 PR,第八天更是达到 10 个。我曾真心怀疑它是否适用于其他人,但我和 Vaibhav 在 7 小时内完成了 3.5 万行可运行的 BAML 代码(若你还不认识 Vaibhav,他是我见过在代码设计与质量方面最一丝不苟的工程师)。
未来规划
我相当确信编程助手将会变得普及化。
困难的部分在于团队和工作流程的转型。在 AI 编写我们 99% 代码的世界里,所有关于协作的方式都将发生改变。
而且我坚信,如果你不解决这个问题,就会被已经解决这个问题的人远远甩在身后。
好吧,看来你显然有东西要推销给我
我们对规范优先、智能体驱动的工作流程非常看好,因此正在开发工具来简化这一过程。在众多事务中,我尤其专注于解决大型团队如何协作扩展这些“高频意图压缩”工作流的难题。
今天,我们正式推出 CodeLayer——这款全新的“后 IDE 时代 IDE”现已开启小范围测试,堪称“面向 Claude Code 的 Superhuman”。如果你既是 Superhuman 和/或 vim 模式的拥趸,又已准备好超越“氛围编程”模式,认真开始用智能体进行开发,我们诚邀你加入等候名单。
请访问 https://humanlayer.dev 注册
致开源维护者——让我们携手共创成果
如果你是旧金山湾区复杂开源项目的维护者,我在此公开提议——周六我会在旧金山与你面对面协作7小时,看看我们能否共同完成重大成果。
通过这种方式,我能深入了解这些技术的局限性及不足之处(如果顺利的话,还能收获一个已合并的高价值 PR 作为实证)。而你将以我验证过最高效的方式——直接的一对一协作,掌握这套工作流程。
致工程团队领导者
若您或您认识的工程负责人希望借助 AI 将团队效率提升十倍,我们正面向 10-25 人规模的工程组织提供前沿部署服务,助力团队完成向 AI 优先编程时代转型所需的文化/流程/技术变革。
感谢
感谢所有在本文早期杂乱版本中耐心倾听的朋友和创始人们——亚当、乔希、安德鲁,以及许许多多的其他人
感谢桑迪普在这场疯狂风暴中的坚守
感谢艾莉森、杰夫和杰瑞德拖着我们连踢带喊地迈向未来
原文链接:
https://github.com/humanlayer/advanced-context-engineering-for-coding-agents/blob/main/ace-fca.md